Backup Leonardo Duarte
O que é a Replicação de Dados?
O que é a Replicação de Dados?
A replicação de dados é o processo de copiar dados de um local para outro. A tecnologia ajuda uma organização a ter cópias atualizadas de seus dados no caso de um desastre.

A replicação pode ocorrer em mais de uma área sendo na rede de área de armazenamento , rede de área local ou local rede de área ampla , bem como para a nuvem . Para fins de recuperação de desastre (DR), a replicação normalmente ocorre entre um local de armazenamento primário e um local externo secundário.
Abordagens para replicação de dados
Existem quatro lugares onde a replicação pode acontecer: no host, hipervisor, storage array ou rede. A replicação baseada em matriz já foi o método dominante, mas os outros ganharam popularidade.
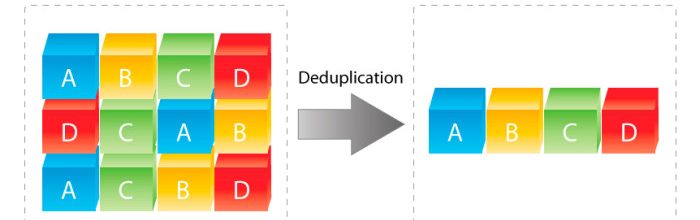
A replicação baseada em host usa servidores para copiar dados de um site para outro, usando o software em servidores de aplicativos. Geralmente é baseado em arquivo e assíncrono. O software de replicação baseado em host inclui capacidades como deduplicação , compactação , criptografia e limitação .
A replicação baseada em hipervisor é um tipo de replicação baseada em host que replica máquinas virtuais inteiras de um servidor host ou cluster de host para outro. Por ser especificamente projetado para VMs, a replicação do hipervisor facilita o failover para a replicação, se a cópia primária da VM for perdida. E pode ser executado em servidores que não suportam nativamente a replicação. Toda replicação baseada em host usa recursos da CPU, o que pode afetar o desempenho do servidor.
A replicação baseada em matrizes permite que matrizes de armazenamento compatíveis usem software interno para copiar dados automaticamente entre matrizes. A replicação baseada em matriz é mais resiliente e requer pouca coordenação interdepartamental quando implantada. Mas é limitado a ambientes de armazenamento homogêneos, pois exige matrizes de origem e de destino semelhantes .
A replicação baseada em rede requer um switch ou appliance extra entre arrays de armazenamento e servidores. A replicação baseada em rede normalmente ocorre em ambientes de armazenamento heterogêneos – ela funciona com qualquer array e suporta qualquer plataforma host. Há menos produtos de replicação baseados em rede no mercado em comparação com ofertas baseadas em array e em host.
Replicação Síncrona vs. Assíncrona
A replicação de dados pode ser síncrona ou assíncrona , dependendo de quando ocorre.
A replicação síncrona ocorre em tempo real e é preferida para aplicativos com objetivos de baixo tempo de recuperação que não podem perder dados. É usado principalmente com aplicativos transacionais de última geração que exigem failover instantâneo no caso de uma falha. Essa abordagem de replicação é mais cara e cria uma latência que retarda o aplicativo principal.
A replicação síncrona é suportada por produtos de replicação baseados em array e em rede, mas raramente em produtos baseados em host.
A replicação assíncrona é demorada. Ele é projetado para trabalhar em distâncias e requer menos largura de banda .
Essa replicação é destinada a empresas que podem suportar objetivos de ponto de recuperação mais longos . Como há um atraso no tempo de cópia, as duas cópias de dados podem não ser sempre idênticas. A replicação assíncrona é suportada por produtos de replicação baseados em array, rede e host.
Replicação de dados com outras tecnologias
A replicação de dados é uma tecnologia fundamental para a recuperação de desastres . Geralmente, ela é combinada com a tecnologia de instantâneos , que permite aos usuários replicar dados periodicamente e, ao mesmo tempo, ser capaz de reverter para um ponto específico no tempo da recuperação. A desduplicação – que elimina dados redundantes – também é freqüentemente combinada com replicação para DR e backup. O Dedupe ajuda na replicação, exigindo que menos dados sejam movidos pela rede.