
Backup Leonardo Duarte
Deduplicação de Dados
O que é a Deduplicação de Dados?
A deduplicação de dados – geralmente chamada de compactação inteligente ou armazenamento de instância única – é um processo que elimina cópias redundantes de dados e reduz a sobrecarga de armazenamento .
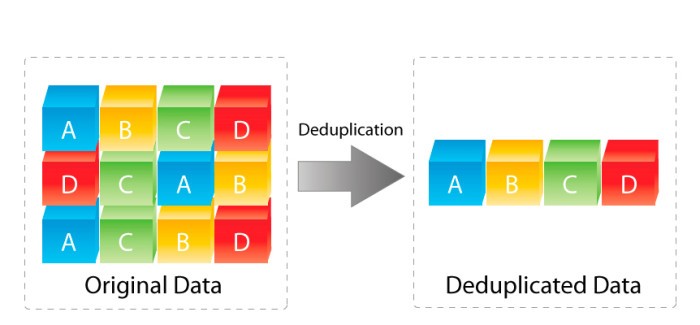
As técnicas de deduplicação de dados garantem que apenas uma única instância de dados seja retida na mídia de armazenamento, como disco , flash ou fita . Blocos de dados redundantes são substituídos por um ponteiro para a cópia de dados exclusiva. Dessa forma, a deduplicação de dados é alinhada com o backup incremental , que copia apenas os dados que foram alterados desde o backup anterior.
Por exemplo, um sistema de email típico pode conter 100 instâncias do mesmo anexo de arquivo de 1 megabyte (MB). Se a plataforma de email tiver backup ou for arquivada, todas as 100 instâncias serão salvas, exigindo 100 MB de espaço de armazenamento. Com a deduplicação de dados, apenas uma instância do anexo é armazenada; cada instância subsequente é referenciada de volta para a cópia salva. Neste exemplo, uma demanda de armazenamento de 100 MB cai para 1 MB.
Deduplicação de meta x origem
A deduplicação de dados pode ocorrer no nível de origem ou de destino.
A dedupe baseada na origem remove blocos redundantes antes de transmitir dados para um destino de backup no nível do cliente ou do servidor. Não há hardware adicional necessário. A deduplicação na origem reduz o uso de largura de banda e armazenamento.
Na dedução baseada em destino , os backups são transmitidos por uma rede para um hardware baseado em disco em um local remoto. O uso de metas de deduplicação aumenta os custos, embora geralmente forneça uma vantagem de desempenho em comparação com a dedução de origem, principalmente para conjuntos de dados em escala de petabytes .
Técnicas para deduplicar dados
Existem dois métodos principais usados ??para deduplicar dados redundantes: deduplicação em linha e pós-processamento. Seu ambiente de backup determinará qual método você usa.
A deduplicação em linha analisa os dados à medida que são ingeridos em um sistema de backup. As redundâncias são removidas à medida que os dados são gravados no armazenamento de backup. A dedução em linha requer menos armazenamento de backup, mas pode causar gargalos. Os fornecedores de storage array recomendam que as ferramentas de deduplicação de dados em linha sejam desativadas para armazenamento primário de alto desempenho.

